張亞勤 AI大模型時代的數據處理與存儲服務革新

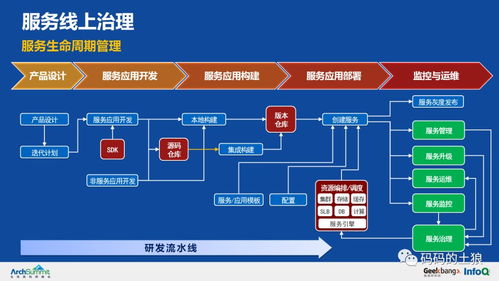
在AI大模型技術迅猛發(fā)展的今天,數據處理和存儲服務正迎來深刻變革。作為行業(yè)領軍人物,張亞勤指出,大模型對數據的依賴程度遠超以往,這不僅要求傳統存儲架構具備更高的吞吐量與低延遲能力,還推動了智能數據治理的進步。只有在云邊端協同、異構計算融合的背景下,數據處理和存儲服務才能支撐起萬億參數模型的訓練與推理。此類服務不再只是硬件擴展,而是需要結合AI全生命周期進行針對性優(yōu)化,包括隱私保護和能耗管理等方面的突破。張亞勤強調,全球化視野下的數據合規(guī)性和高性能需求既是挑戰(zhàn)也是機遇,將為計算基礎設施的未來建設奠定基礎。唯有依托最優(yōu)的數據處理與存儲持續(xù)迭代,方能真正釋放大模型的巨大潛能。智能時代,沒有穩(wěn)健且智能化的數據底座,一切都將是空談。因此,圍繞這一基礎技術的有序演進,必然會在未來贏得越發(fā)廣泛的關鍵價值成果激勵推動各行業(yè)創(chuàng)新發(fā)展路徑。
如若轉載,請注明出處:http://m.nhxingfa.cn/product/87.html
更新時間:2026-06-13 16:13:15